Can your agent keep a secret?
Good Morning!
These preprints ask two uncomfortable questions: are our evaluation benchmarks lying to us, and can agents be hijacked mid-task?
1. Perturbation prediction benchmarks are broken
Vollenweider et al. argue that standard benchmarks for high-dimensional biological perturbation prediction — the class of models that forecast how cells respond to genetic or chemical interventions — systematically overestimate model quality because of signal leakage, weak baselines, and poorly chosen evaluation metrics. The bioRxiv preprint lays out three corrective principles: define a signal ceiling, require matched null baselines, and report metrics that reflect true predictive gain. Teams running CRISPR-screen or drug-response prediction pipelines are almost certainly using evaluation setups this paper would flag as misleading. Read More →
Why it matters: Any lab buying or building a perturbation-prediction model now has a concrete three-point checklist to apply before trusting a vendor benchmark or an internal validation number.
2. MCP agents vulnerable to function hijacking
Belkhiter et al. demonstrate a class of attacks they call function hijacking against agents that use MCP (Model Context Protocol, Anthropic's open spec for letting AI agents call external tools). A malicious tool description can silently redirect an agent to call a different function with attacker-controlled arguments — without any visible sign to the user or the orchestrating model. For biomedical teams routing agents against EHR APIs, lab instrument APIs, or clinical databases over MCP, this is an active threat surface, not a theoretical one. Read More →
3. Multimodal AI composer for RNA design
Pinpin et al. introduce yakRNA Design, a semantic multimodal system that combines sequence, structure, and natural-language intent to compose RNA molecules. The bioRxiv preprint positions the tool as an interactive design interface rather than a one-shot predictor, letting researchers specify functional goals in prose and iterate — a workflow closer to how bench scientists actually think about RNA engineering. Read More →
4. Pan-bacterial protein expression predictor
Tien et al. release Aiki-XP, a multimodal model predicting within-species relative protein expression across bacteria at pan-bacterial scale, with explicit leakage-controlled evaluation — a methodological choice that directly addresses the benchmark-integrity issues raised this same weekend by Vollenweider et al. Read More →
5. New benchmark for motif-preserving protein generation

Strashnov et al. publish GeomMotif, a benchmark testing whether protein generative models preserve arbitrary geometric motifs — active sites, binding interfaces, metal-coordination shells — rather than just global fold quality. Existing protein-generation evaluations largely miss this requirement. Read More →
6. Benchmarking agent data-privacy compliance
Fu et al. introduce CI-Work, a benchmark for contextual integrity (the principle that information should flow only in ways appropriate to its context) in enterprise LLM agents — directly relevant to any team deploying agents against patient records or proprietary assay data. Read More →
7. Small tool-use agents trained at industrial scale
Lyu et al. describe AgenticQwen, a framework for training compact LLM agents on tool use at industrial scale using dual data flywheels — a self-reinforcing loop where model outputs generate more training data, which improves the model. Read More →
8. Structured memory for long agent tasks
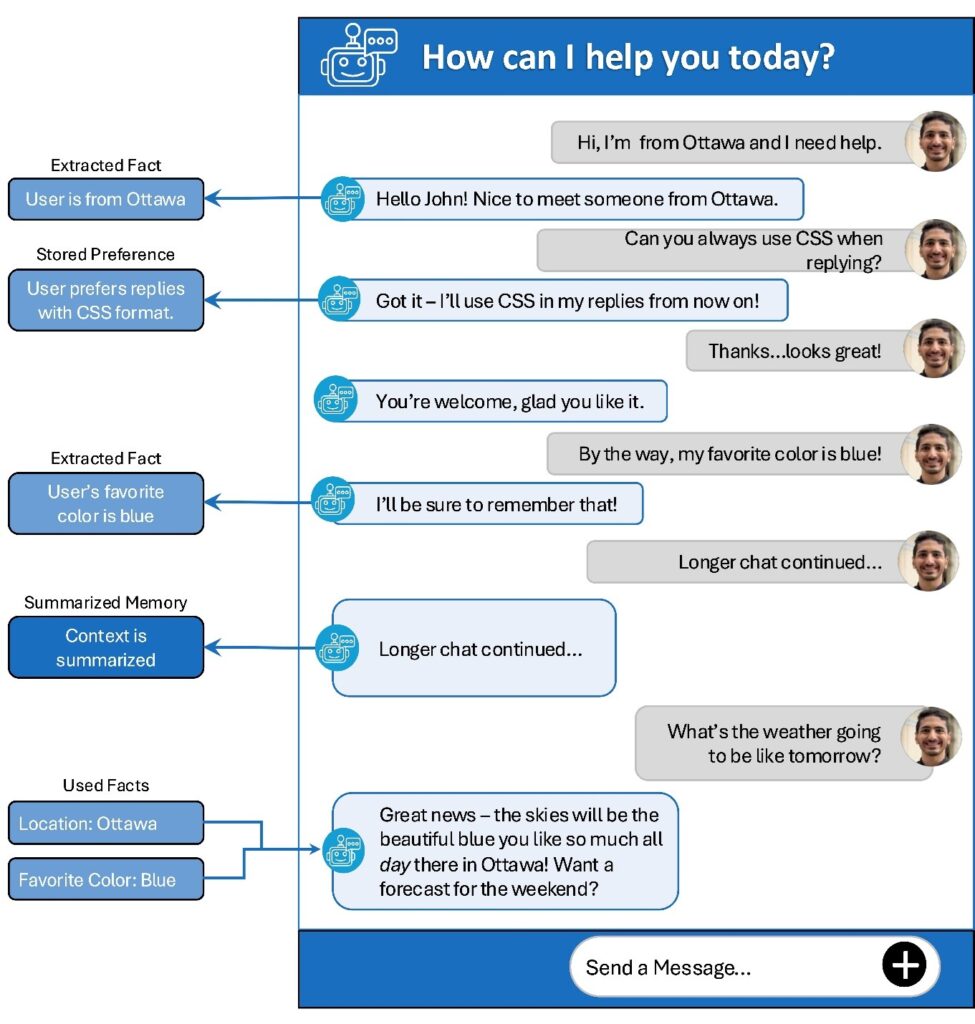
Xu et al. propose StructMem, a structured memory architecture (think indexed, typed records rather than raw text history) for helping LLM agents maintain coherent behavior across long multi-step tasks. Read More →
9. Verbal critiques sharpen LLM reasoning
Chen et al. show that process supervision via verbal critique — having a model narrate step-by-step errors in its own reasoning — improves accuracy on complex reasoning tasks more than outcome-only feedback. Read More →
10. Inferring clinical events from timestamped data
Awuklu et al. formalize the computational complexity of inferring high-level clinical events from timestamped EHR records, with algorithmic results and medical case studies. Read More →
Reply to talk back — this email comes to a human (newsletter@heurekalabs.co). Forward freely.
Agentic Discovery is a project of Heureka Labs · Unsubscribe